





















做機器學習,數據和模型哪個重要?吳恩達的「二八定律」告訴你真相

機器學習的進步是模型帶來的還是數據帶來的,這可能是一個世紀辯題。
吳恩達對此的想法是, 一個機器學習團隊 80% 的工作應該放在數據準備上,確保數據質量是最重要的工作 ,每個人都知道應該如此做,但沒人在乎。如果更多地強調以數據為中心而不是以模型為中心,那麼機器學習的發展會更快。
機器學習模型成效不好,應該先處理「數據」
當去 arxiv 上查找機器學習相關的研究時, 所有模型都在圍繞基準測試展示自己模型的能力 ,例如 Google 有 BERT,OpenAI 有 GPT-3,這些模型僅解決了業務問題的 20%, 在業務場景中取得更好的效果需要更好的數據 。
傳統軟體由程式碼提供動力,而 AI 系統是同時使用程式碼(模型+演算法)和數據構建的。 以前的工作方式是,當模型效果不理想,我們就會去修改模型,而沒有想過可能是數據的問題 。
機器學習的進步一直是由提高基準數據集性能的努力所推動的。研究人員的常見做法是在嘗試改進程式碼的同時保持數據固定,以模型改進為中心對模型性能的提升實際上效率是很低的。但是,當數據集大小適中(<10,000 個範例)時,則需要在程式碼上進行嘗試改進。
做機器學習,數據少、數據大都有挑戰
根據劍橋研究人員所做的一項研究,最重要但仍經常被忽略的問題是 數據的格式不統一 。當數據從不同的源流式傳輸時,這些源可能具有不同的架構,不同的約定及其儲存和訪問數據的方式。對於機器學習工程師來說,這是一個繁瑣的過程,需要將訊息組合成適合機器學習的單個數據集。
小數據的劣勢在於少量的噪聲數據就會影響模型效果,而大數據量則會使標註工作變得很困難,高質量的標籤也是機器學習模型的瓶頸所在。
這番話也引起機器學習界對 MLOps 的重新思索。
MLOps 是什麼?
MLOps,即 Machine Learning 和 Operations 的組合,是 ModelOps 的子集,是數據科學家與操作專業人員之間進行協作和交流以幫助管理機器學習任務生命週期的一種實踐。

與 DevOps 或 DataOps 方法類似,MLOps 希望提高自動化程度並提高生產 ML 的質量,同時還要關注業務和法規要求。
網路公司通常用有大量的數據,而如果在缺少數據的應用場景中進行部署 AI 時,例如農業場景,你不能指望自己有一百萬台拖拉機為自己收集數據。
發展 MLOps,吳恩達有話要說
基於 MLOps,吳恩達也提出幾點建議:
1.MLOps 的最重要任務是提供高質量數據
2.標籤的一致性也很重要。檢驗標籤是否有自己所管轄的明確界限,即使標籤的定義是好的,缺乏一致性也會導致模型效果不佳
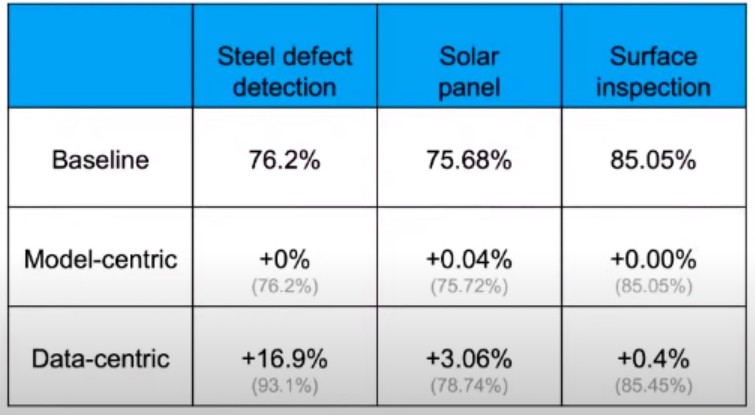
3.系統地改善 baseline 模型上的數據質量要比追求具有低質量數據的最新模型要好
4.如果訓練期間出現錯誤,那麼應當採取以數據為中心的方法
5.如果以數據為中心,對於較小的數據集(<10,000 個樣本),則數據容量上存在很大的改進空間
6.當使用較小的數據集時,提高數據質量的工具和服務至關重要
一致性的數據定義,涵蓋所有邊界情況,從生產數據中得到及時的反饋,數據集大小合適。
吳恩達同時建議,不要指望工程師去嘗試改善數據集。相反, 他希望 ML 社群開發更多 MLOps 工具,以幫助產生高質量的數據集和 AI 系統,並使他們具有可重複性 。除此之外,MLOps 是一個新生領域,MLOps 團隊的最重要目標應該是確保整個項目各個階段的高質量和一致的數據流 。
這些 MLOps 工具,可以協助你做機器學習
一些 MLOps 的工具已經取得了不錯的成績。
Alteryx 處於自助數據分析運動的最前沿。公司的平台「Designer」旨在快速發現、準備和分析客戶的詳細訊息。該工具用於易於使用的界面,用戶可以連接和清除數據倉庫。Alteryx 的工具還包括空間文件的數據混合,可以將其附加到其他第三方數據。
Paxata 提供自適應的訊息平台,它具有靈活的部署和自助操作。它使分析人員和數據科學家可以收集多個原始數據集,並將它們轉換成有價值的訊息,這些訊息可以立即轉換為執行模型訓練所需要的格式。該平台是基於「所見即所得」設計,具有電子表格風格的數據展示,因此用戶無需學習新工具。此外,該平台能夠提供演算法協助以推斷所收集數據的含義。
TIBCO 軟體最近在這個快速發展的領域中嶄露頭角。它允許用戶連接、清理、合併和整理來自不同來源的數據,其中還包括大數據儲存。該軟體使用戶可以透過簡單的線上數據整理進行數據分析,並且提供完整的 API 支持,可以根據自己的個性化需求進行更改。
網友表示,吳恩達老師說的太真實了!

也有網友表示,機器學習更像是數據分析,模型的搭建就是構建 pipelines。
出處 : TechOrange科技報橘

